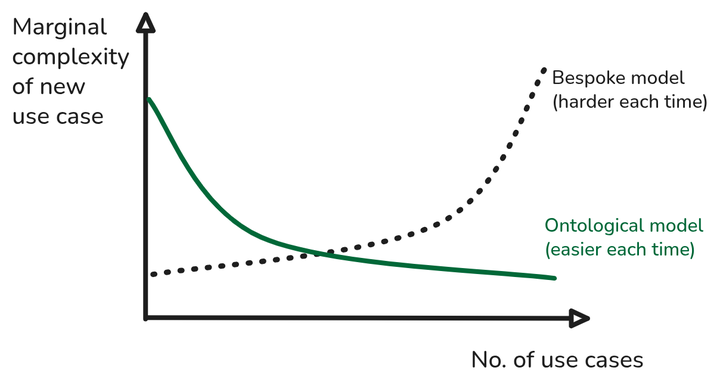
Traditional MES vendors treat digitization as a series of isolated problems. Each use case has a set solution that the manufacturer must fit to their operation. To implement a new use case, you need a new module, perhaps different data structures, and maybe even a new vendor.
Rhize’s Manufacturing Data Hub (MDH) flips this approach on its head. We start with a data model that is flexible enough for all cases, ISA-95. This model forms the basis of our database schema, which users interact with through our API and workflow engine. This headless approach gives the user a platform to implement their use case in the most minimal and appropriate way—while maintaining sustainable governance and data quality.
Each new use case builds on top of existing ones, creating a use-case stack that compounds in value over time. It also unlocks new value from systems integration, uniting specialized systems from the business, operation, and controls domains in a standardized integration hub.
Related video: Solving for Innovation of Use Case Development
The progressive stack of use cases
An example is the best way to demonstrate what we mean.
Most companies start a digital transformation by measuring performance, so we’ll start there too. Since it’s a “classic” (for better or worse), let’s use OEE. But don’t get hung up on the example metric―the real point is to show how one use case paves the way for the next.
Example base case: starting with metrics
OEE is a composite measure, composed of metrics about availability, performance, and quality.
In ISA-95 terms, the most minimal OEE use case really only needs to model the relevant equipment, operations capability, and material.
- To derive availability, you can compute a metric from the Equipment state properties
- To calculate performance, use the ideal cycle time contained in the capability.
- To calculate quality, measure the amount of good material produced against the amount of scrap.
That’s really all you need to model for a real-time check of operational efficiency. However, it’s not very much on its own. So let’s extend this model to incorporate broader business perspectives and use cases.
Adding scheduling data
Perhaps your realtime monitoring exposes a need to optimize production schedules. For this use case, extend your foundational model to incorporate information about business planning. In most operations, this data originates from the ERP.
To integrate scheduling data into your ISA-95, you can map the planning data into Operations Request entities, and report the information about performance back as Operations Responses. If you want to include level three data about the order, your data may also include Job Requests and Job Responses. In fact, you might even extend your metrics to include a measure of performance that compares work planned against work actually done―in ISA-95 entities, this might be the request duration and response.
Now notice how your use case has stacked to integrate across three different functions: the ERP represents the business-planning view, the raw data about machine state might be stored in a time-series database, and the overall view of the operation is captured in your ISA-95 data hub.
Integrating with testing systems
From here, you may discover that your quality tests are creating a significant bottleneck in production. This may be time to invest in digitizing your quality procedure, which also provides an opportunity to extend your knowledge graph through the testing model and your integration with a specialized quality-testing system.
ISA-95 has an entire category devoted to testing. For your existing module, you might extend the batch’s job response object to include a test result from your material samples.
Now you’ve got a use case stack. It handles scheduling, realtime measurement, and quality assurance, and integrates with data at various levels of granularity, from business to plant controls, and covering systems with responsibilities, from scheduling to quality.
Porting the stack to new sites
Multi-site MES deployments have historically been extremely difficult. Often, firms end up with essentially two separate systems that handle the same use case.
With the MDH approach, your use cases are portable. The logic in your MES layer is abstract, represented as it is by an ISA-95 model. Rather than inventing a new data model for a new site, you can just adapt the use cases to the particularities of its equipment and capabilities.
In the case of our use case stack, you now have far richer data to mine and analyze. Why is quality so much better in Site A than Site B? How can we adjust our schedules for different throughputs and comparative efficiencies?
These questions may drive new changes, metrics, and points of integration. New use cases for the stack!
Every use case enhances the next
The beauty of this approach is that you start minimally: first, exactly as much as you need for your use case. As you add use cases, each use case integrates into the [context] of your overall knowledge graph.
The data model stays the same, only growing richer and more connected. This is a revolutionary way to think of MES deployment.