As the “hub” in its name implies, a manufacturing data hub is a repository for all data that pertains to a manufacturing operation. But what exactly does “all data” mean? As manufacturing veterans know, manufacturing data exists at many levels:
- From sensors
- From execution systems
- From the level of the business operations
- At the aggregate level, for analytics
An MDH can work with all these data sources and formats. This article looks at the structure of this data along with its pros and cons.
The types of data that can enter the MDH
#1. Discrete Values

The first type of data that the MDH can ingest is tag-system data. Tag data comes from machines and sensors on the factory floor. These machines and sensors typically communicate and create data over protocols such as OPC UA and MQTT. Their values are usually in primitive data types such as booleans, floats, strings, and integers.
Little to no context surrounds discrete data values. Discrete values typically arrive from a high-frequency stream. Alongside the value there may be some other metadata associated with it such as:
- Value
- Value type
- Unique identifier
- Time of origin
And perhaps:
- Place of origin
- Unit of measure
- Quality
A common point of interaction for discrete or tag data is through a SCADA system.
While lightweight, tag data on its own provides little information about the broader manufacturing operation. As much as the data has context, it is limited to the representation of the AddressSpace or MQTT topic structure. However, when integrated with other data, this data can form part of the entire manufacturing system of record.
#2. Complex Data Objects
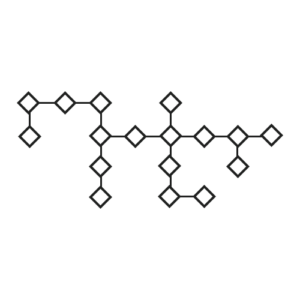
At the core of the MDH is its standards-enforced graph database. This data has built-in context, as it is part of a schema that models all manufacturing entities. The structure of the data is complex, normally a mix of hierarchical and network relationships. Rather than a row, column, or topic, the data is structured through a series of nodes and connections that represent the complex relationships present in a manufacturing operation.
Typically, users query complex data through an API, such as the Rhize GraphQL API. In the manufacturing operation, this data works with the MES and dashboarding of the operation. As the center of the manufacturing data hub, the graph database brings advantages both for user experience and for its technical capabilities:
- With GraphQL, you can precisely define the data you need at query time, specifying both the types and fields of interest. This eliminates over-fetching and under-fetching issues commonly encountered with REST/SQL methods
- Navigating through complex network relationships is intuitive with graph databases. Unlike SQL, which requires cumbersome and performance-costly joins to link tables, graph databases natively support these connections, making queries both simpler and faster.
- Handling hierarchical data structures is straightforward with graph databases. Graph databases naturally support recursive queries, which can be challenging and inefficient in SQL due to the need for nested joins. This flexibility provides an elegant and efficient way to explore of hierarchical relationships.
- All data that enters the graph forms associations, bringing rich context for reporting and analytics.
- The graph structure is a perfect architectural match for a data model built on ISA-95.
- The database can scale horizontally and is ACID-compliant.
However, while complex graph data represents the facet of manufacturing execution with great fidelity, many stakeholders from the business and analytics departments may prefer or require a traditional relational database.
#3. Row-Oriented Data
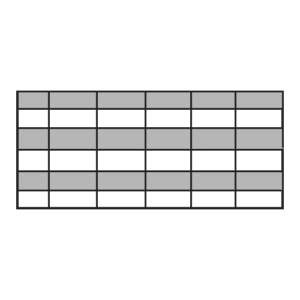
The MDH can ingest, transform, store, and emit row-oriented data as required.
Row-oriented data is structured in rows and columns within tables. Each row represents a complete record or entity, and each column contains a specific attribute or field related to that entity. This is efficient for transactional operations (OLTP) where entire records are frequently read or modified at once.
Row-oriented is the traditional way to organize data in many relational databases, and examples include Postgres and MySQL. Row-based relational databases have a long history of success, and they have wide support across platforms and tools through variations of SQL.
However, when it comes to analytical queries that aggregate data across many records, row-oriented storage can be less efficient, because it may need to read more data into memory than is necessary for the specific query.
Large-scale data processing compound this inefficiency, especially in a manufacturing operation where millions of rows are generated.
#4. Column Oriented Data
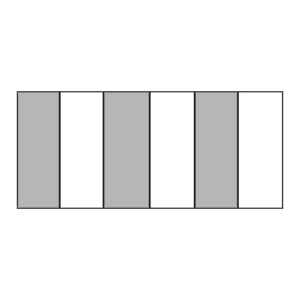
Lastly, the MDH can ingest, transform, store and emit Column-Oriented data as required.
Column-oriented databases store data by columns. This approach is optimized for read-heavy analytical operations where users query specific columns across many rows. By only loading the required columns into memory, columnar databases can reduce the I/O load.
This allows for efficient data retrieval from specific columns across many rows, making analytical queries and large-scale data processing much more efficient, especially for extracting and manipulating data like time-series data.
Other advantages of column-oriented data include better data compression and storage with missing or sparse fields. Examples of column-oriented databases include Influx and QuestDB (specializing in time-series data) and Snowflake and DuckDb (which serve general needs in Online Analytical Processing).
Column-oriented data is used heavily in data-science and machine-learning projects because of its ability to be used and manipulated at large data scales.
Column-oriented data is less efficient for transactional workloads. It’s not ideal for operations that require frequent updates to individual rows or records. This also makes retrieval of a complete record difficult. Column orientation also makes querying more complex, especially when used for both operational and analytical purposes.
ACID compliance is a low priority with column-oriented data.
It takes a hub
Every method of storing and representing data brings tradeoffs. In large scale manufacturing operations, data is diverse, multi-faceted, and often flows at massive scale.
It takes a hub to bring all this data together! For example, in Rhize, these are all common patterns of data ingestion and integration:
- Sensor data gets associated with a data source and equipment, which is part of the complex graph data
- The same equipment associated with sensor readers also gets associated with job orders, which might originate in the business-level, transactional database.
- Special values and tags may get persisted to a time-series database to provide a way to efficiently perform large-scale calculations on metrics such as OEE.
- Highly contextualized subsets of data can be exported to column-oriented parquet files, for storage in column-oriented data lakes.
The MDH is designed to offer various options for data storage and representation, depending on the use case requirements. These flexible architecture options reduce the tradeoffs inherent in an environment where fewer options are available. The pre-integrated nature of these components, alongside carefully chosen transform and processing options, offers a suite of proven architecture patterns right out of the box. This shortens time to value for a given use-case.