
Contextualization is an enduring goal for people who work with manufacturing data. As with anything, a manufacturing object or measurement makes sense only when we can know its origin and can compare it to other values.
Given its importance to all human experience, however, the way that manufacturers and vendors typically think of context is far too narrow. Context is not only a unit of measurement with a timestamp, or an equipment ID and its position in the broader hierarchy of the plant. All these things are important, but knowing the deeper context requires answers to many more questions, such as:
- What process was this value a part of?
- How is this process defined?
- What generated the demand for this process?
- What material, people, and physical items were part of this process?
- Have these resources ever been reused?
- Did the process perform to expectations?
- How does performance compare to similar processes that happened at different times or in different areas?
Such questions could go on forever, which leads to a practical problem: deepening context requires an increasingly complex model of the world.
However, we argue that building a system that can provide the deep context of manufacturing is not a pipedream or even theoretical. It requires two things:
- An ontology, or standardized vocabulary to discuss all things in manufacturing in relation to each other
- A hub, or a system that can gather data from all systems and position it within an ontology
Going beyond the process data
Conversations about “context” in manufacturing are conventionally bound to the process perspective of an operation. As you get more nuanced, you can tease out different levels of context that exist at this low-level view:
- The time stamp and equipment ID
- A visualization of this time-series
- Calculations of metrics and values from this data.
These are all valuable, but they remain with the controls-centric perspective. Full context has broader views.
The Manufacturing view
All manufacturing produces some kind of final good or “lot.” While process data delivers granular data about execution state and time, the lot defines the product as an identifiable unit that conforms to a defined standard and was created thanks to the conscious work of people using equipment to create new material.
Information about performance, demand, definitions, and capabilities all require thinking of manufacturing as a composition. While process data can tell us that a vessel that contains liquid at such temperature and such pressure, we need a data model for manufacturing operations to be able to represent information like:
- Which machines belong to which orders
- How materials move between processes.
- Which machines depend on which resource
The operational view
Even in the most worker-empowered plant, the business side of the organization always manages some aspects of production. Conventionally, production schedules, master recipes, and high-level decisions about inventory and capabilities are managed from the top. Thus the full level of context includes this operational information as well.
Joining data from the process, operations, and business perspectives is the only way to have a coherent, singular picture of everything that went into a production run, from the operations schedule that initiated all the work within the plant to the bare tag value that measures a few milliseconds of work being performed.
The aggregate view
Thus far, we’ve discussed a view of context that joins the vertical hierarchy of the business with the flow of execution in time. But context has even greater depth when we consider that most events happen more than once. Thus context also exists at an aggregate level.
As a business repeats processes, it has more and more opportunity to compare the previous contexts across time and across production areas.
The ontology of manufacturing
While the previous section describes a fuller picture of where context exists, it overlooks two large problems:
- If we cannot relate these levels of context in a uniform view, then we are not speaking of one “context” but of many.
- The complexity of relating these levels together requires a large, interrelated schema.
To overcome these issues, context requires an ontology of all manufacturing relations.
Fortunately a perfectly suitable ontology already exists: the ISA-95 standard. The scope of this article is about how ISA-95 informs context, but if you want a proper introduction to what ISA-95 is, read our guide, How to speak ISA-95.
A way to precisely describe entities, and relations.
ISA-95 provides a generic vocabulary to describe entities at different dimensions of time (e.g. past, present, future) and different levels of abstraction (e.g. as a definition of work or as a real performance of that work). Its relationships create a graph of all these entities, so that each model relates to others. For example, an operations schedule contains a demand for work, which relates to a specific order dispatched to a specific group of resources, which are used to create the good, and whose performance can be compared to the original schedule to view capability.
This system of terminology and relationships is the exact basis for Rhize’s data model, which uses an ISA-95 schema to store relations in a graph database. For details of why these technological decisions were made, read Reframing your Perspective on ISA-95.
A way to describe and store interaction
Thus far we have discussed ISA-95 as a data model, but it also corresponds to a standard set of terminology for all humans involved in the operation. ISA-95 as an ontology provides a way of thinking and speaking about an operation. This standardized ontology removes ambiguity about what a thing in a manufacturing operation is or does.
So the ISA-95 ontology, and the context that it brings, is also a way of enforcing a high degree of data governance. And, if the data model uses ISA-95 as a backend, everyone who understands the basics of ISA-95 can also understand the basics of the MES, even people who don’t ever query, model, or touch code.
This reduces the cognitive complexity of all people and machines across the organization.
A contextualized hub for all data
So much for the “impossible” idea of a fully contextualized data model: it already exists as a graph database that uses an ISA-95 ontology as its schema. However, the schema has no value if it doesn’t store real manufacturing data. That is the second component of the data hub: it must provide ways to incorporate various sources of data in a standard way.
In Rhize: here are some ways that happens:
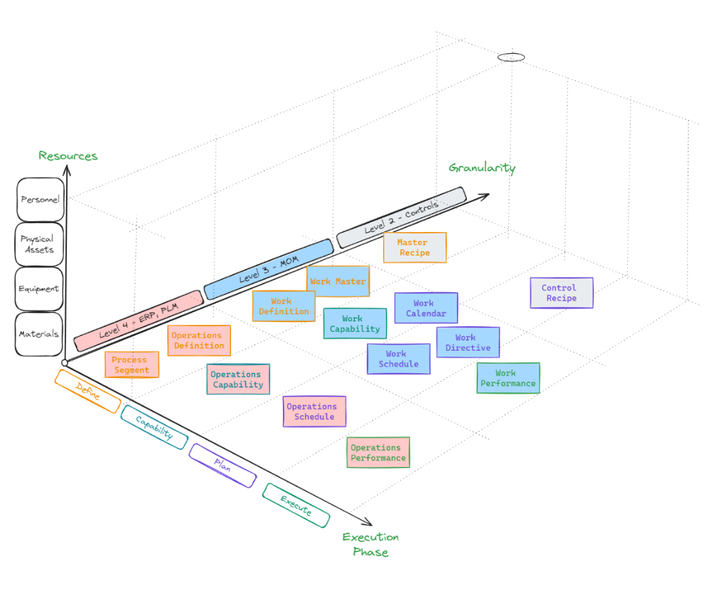
- Level-4, or business-level, data enters the system through integrations with the ERP. It can also be generated out of some data that is processed during level-3 execution and subsequently sent back to the ERP system. Level-4 objects are all given an
operationsprefix, and their context with the corresponding level-3 functions are built-in through their relationships with manufacturing, orworkentities. - Level-3, or manufacturing-operations data, is gathered and created along all the activities of scheduling, dispatching, execution, and collection.
- Level-2, or controls, data enters the system via integrations with data sources like MQTT and OPC UA servers. It is contextualized with level-3 performance models through the
jobResponsedata, various equipment properties, testing results, and so on.
The graph database represents the brain of the manufacturing data hub. But a data hub also integrates with other representations and stores, like time-series, columnar, and row-oriented databases. For details, read about the data that goes into a data hub.
Finally, let’s stress that context is part of what separates a manufacturing hub from a data lake. Though you can use the data hub as an input for the lake, the built-in ontology exists in a database only when that database has a schema to model the entities and relationships.
This is a reality
The application with an architecture for deeply contextualized manufacturing data already exists, and real customer implementations are running on top of this application, gathering data in an ever deepening context. This means that the value of Rhize and its data enriches with time and with use cases.
As you build more on Rhize, you have more data to compare. As you extend Rhize’s use cases, you incorporate more data across relationships―horizontal, vertical, and abstract―creating a deeper context to understand what each thing is and does in the grand and small views of the manufacturing operation.